

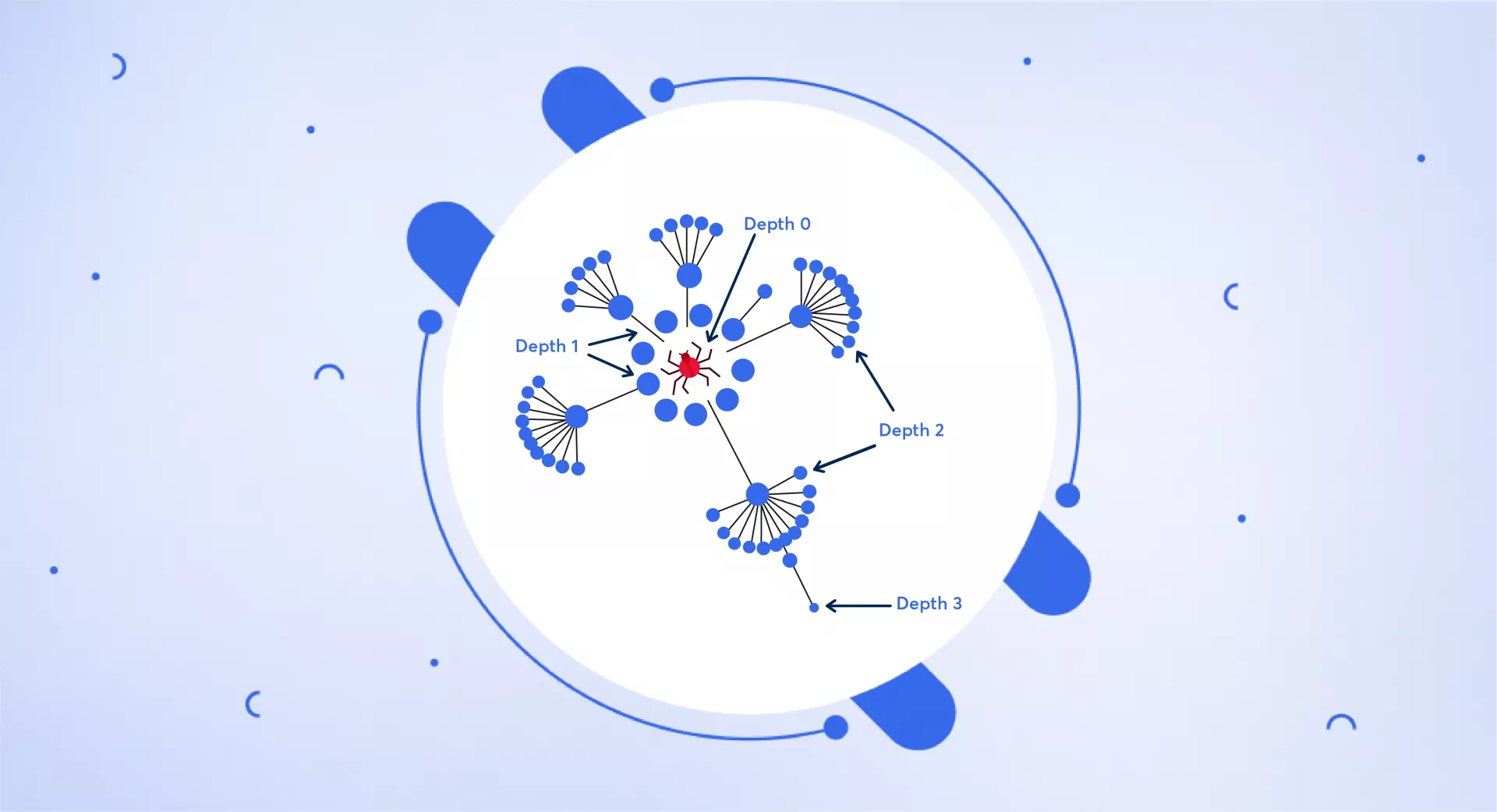
What is Crawl Depth?
Crawl depth refers to how many clicks deep a search engine bot goes into a website to find and catalogue pages.
The bot starts its crawl at the home page of a site. Since the home page is the first page the bot lands on, it has a crawl depth of 0 - it's the starting point.
From the home page, the bot then follows links to other pages on the site. These pages now have a crawl depth of 1, meaning they are one click deeper than the home page.
If the bot clicks links on those pages to reach more pages, those new pages would be at crawl depth 2. And so on as the bot navigates deeper into the site structure.
So crawl depth indicates how many links away from the home page a certain page is located. Pages buried deeper within a site's hierarchy of content have a higher crawl depth number.
There's no one ideal crawl depth that works for all websites though. It depends on factors like site design and content structure. But knowing crawl depth helps understand how search engine bots explore and index pages.
Is there a value of crawl depth for a specific page?
There is no specific value for crawl depth that applies to all websites, as the optimal crawl depth can vary depending on factors such as site architecture, content structure, and user experience goals.
However, according to some SEOs, the Home Page of a website is always considered to have a crawl depth of "0" because it is the starting point from which a search engine crawler begins its crawl of a website.
Why is crawl depth important to consider?
Crawl depth is important to consider for several reasons:
Indexing
Search engines use web crawlers to index web pages for their search results.
If the crawler is unable to reach certain pages on a website because of a shallow crawl depth, those pages may not be indexed and won't appear in search results.
Ranking
The pages search engines index are ordered by importance, called ranking. This ranking depends on things like how relevant, high-quality, and authoritative a page is.
If important pages are missed because the crawl depth is shallow, the website's search ranking can suffer.
User experience
A deep crawl also helps improve user experience. It makes sure all a site's pages can be easily found and accessed.
If pages are too buried in a site, users can get frustrated looking for them. This gives a poor user experience.
So a deep crawl helps search engines fully index and rank pages. It also allows users to easily discover all a website's content. This improves search results and user experience.
SEO Audit
A deep crawl can also provide valuable information for SEO audits by revealing any issues with the website's structure, such as broken links or pages with poor internal linking.
This information can be used to optimize the website for better search engine performance.
How to audit the sites for crawl depth?
To audit a website for crawl depth, you can follow these steps:
Determine the crawl depth of your pages
You can use a tool like Screaming Frog to identify how Google crawls your site.
This will give you an idea of how many levels deep the crawler goes on your site before reaching a dead end or encountering a page that is not linked to other pages.
Analyze the crawl path
After determining the crawl depth of your pages, analyze the crawl path of your website to understand the flow of the crawler.
Look for patterns of pages that are frequently crawled and pages that are not crawled at all. This will help you identify any issues with your site's architecture, such as orphaned pages or pages that are buried too deep.
What are common crawl depth issues?
Here are some common crawl depth issues that websites may experience:
Pagination
When a website has multiple pages of content, such as blog posts or products, it can create crawl depth issues if search engine crawlers are unable to access all of the pages.
This can happen if the pagination is not set up correctly, causing some pages to be inaccessible to crawlers.
Dynamic URLs
Websites that use dynamic URLs can also encounter crawl depth issues, as these URLs can create an endless number of possible page variations, making it difficult for search engine crawlers to identify and crawl all of the relevant pages.
Orphaned pages
Orphaned pages are those that are not linked to from other pages on the website, making them difficult for search engine crawlers to find and access.
These pages may not be crawled and indexed, leading to reduced search visibility and traffic.
301 Redirects
While 301 redirects are often used to improve a site's SEO by redirecting users and search engines to a preferred URL, they can also cause crawl depth issues if not implemented correctly.
If multiple 301 redirects are put in place sequentially, it can increase the crawl depth. This means a search engine may need to go through several redirects before it reaches the intended destination.
Search engines have a limit to how deep they will crawl. If this limit is reached before arriving at the intended page, the search engine may not be able to properly index that page - negatively impacting its SEO.
Broken links
Broken links can prevent search engine crawlers from accessing certain pages, leading to crawl depth issues.
When a crawler encounters a broken link, it may stop crawling that path altogether, missing out on other pages in that section of the site.
Site structure
The overall structure of a website can also impact crawl depth. A poorly structured site with many unnecessary levels or pages can make it more difficult for search engine crawlers to crawl all of the relevant pages.
A well-organized site structure that makes it easy for crawlers to navigate can improve crawlability and ensure that all of a site's pages are accessible to search engines.
Slower load speed
Websites that load slowly can also experience crawl depth issues, as search engine crawlers have a limited amount of time to crawl a site before moving on to the next one.
If a page takes too long to load, it may be skipped over, leading to crawl depth limitations and missed pages.
Pages buried too deep
If some pages on a website are buried too deep within the site hierarchy, it can be difficult for search engine crawlers to find and access them.
This can lead to these pages being missed and not included in search engine indexes, resulting in lower search visibility and traffic.
How do we solve these issues?
Implementing proper pagination markup
Doing this on the website can help search engine crawlers identify and access all pages of the content.
Additionally, including internal links to the previous and next pages in the pagination chain can help to ensure that crawlers are able to reach all pages.
Use a few redirects
To avoid crawl depth issues caused by 301 redirects, it is important to use as few redirects as possible and to make sure that the destination URL is easily reachable by search engine crawlers.
Fixing broken links
Fixing broken links can help search engine crawlers access all pages on a website.
Using a tool like Google Search Console can help website owners identify broken links. It provides a report on all pages that returned a 404 error, indicating a broken link.
This report can be found in the "Coverage" section of Google Search Console, under "Errors". Each error includes the URL of the page where the error occurred, which can be used to find and fix the broken link.
Once identified, broken links can be fixed by updating the link or removing it altogether.
Improving website load speed
It can help search engine crawlers access all pages on a website within their limited crawling time. Website owners can optimize images, minify code, and use content delivery networks (CDNs) to improve load speed.
Improving the site hierarchy
It can help search engine crawlers access buried pages. This can be done by creating internal links from higher-level pages to deeper pages.
Creating internal links
Creating internal links to orphaned pages can help search engine crawlers find and index these pages.
You could add links to these pages in your site's main navigation, within the body text of related pages, or in a footer or sidebar.
Improving the site structure
Making the site structure better can help search engine crawlers access all pages on the website.
Improving site structure for better SEO involves organizing the site hierarchy in a logical way, creating meaningful internal links between pages, using a clear navigation menu, implementing breadcrumbs for easier navigation, and building a sitemap that lists all significant pages.
These steps enhance the understandability of your site for both users and search engines, leading to better SEO performance.
Create XML sitemap
Another solution for addressing crawl depth issues is to create an XML sitemap for the website. An XML sitemap is a file that lists all the pages on a website that the website owner wants search engines to crawl and index.
By submitting an XML sitemap to search engines, website owners can help ensure that all pages on their websites are being discovered by search engine crawlers.
Conclusion
It is crucial to maintain an optimized crawl depth to ensure that your website's important content is easily discoverable by search engines and provides a positive user experience.
By researching and implementing the best strategies for your website, you can improve crawl depth and ultimately drive more traffic to your site.