


What is a Canonical Tag?
A canonical tag – also called rel canonical – tells the search engine that this URL is the precise and most definitive version of a page from a set of many similar or duplicate pages on your website.
If your website can be accessed through multiple URLs like this:
https://www.yourwebsite.com
http://www.yourwebsite.com
http://yourwebsite.com
Google will see this page as a duplicate and choose only one version as a canonical or a standard version of a page, and all other URLs will be considered duplicates or near duplicates.
Without a canonical tag, Google will choose a version itself as the standard one.
Remember that a canonical tag is not a directive; it is only a hint for Google that this is the most appropriate URL version.
You can use Google Search Console to see whether Google has chosen your specified URL as canonical or its own.
Example of a Canonical Tag
The canonical tag is an HTML tag that is placed in the head section of a website. This tag is inserted in the duplicate pages and points toward the page you want Google to pick as canonical.
The basic syntax of a canonical tag is as follows:
<link rel=“canonical” href=“https://www.yourwebsite.com”>Here, the link rel=“canonical” is the canonical tag, attribute, or element, and the link that will be inserted in this tag will be considered as a canonical URL, i.e., href=“https://www.yourwebsite.com shows the URL that is the canonical version of all duplicate pages.
What is a Canonical URL?
Sometimes, the terms canonical tag and canonical URL are used interchangeably. However, there is a slight difference.
A canonical tag tells the search engine that this particular page on which it exists is not the canonical version; rather, the URL it is pointing to is the master copy or the main version.
On the other hand, a canonical URL indicates the URL, which is the master copy or canonical version of a web page.
In <link rel=“canonical” href=“https://www.yourwebsite.com”>
https://www.yourwebsite.com is the canonical URL.
How Google Chooses the Canonical URL?
After indexing a website, Google tries to understand the main content of that website.
If multiple pages have the same content on your website, Google will choose only one as the standard version and mark it as canonical.
To save the crawl budget, Google will crawl the canonical pages more than their duplicate versions.
Google chooses the canonical version of a page by using multiple signals like:
Page quality
Presence of HTTP or HTTPS
“rel=canonical” labelling attributed by the website owner
But that doesn’t mean assigning a “rel=canonical” tag will force Google to mark a page as canonical; it may choose it on its own.
Usually, Google shows the pages marked with canonical tags, but sometimes, it does not. Suppose a user opens a page on mobile; Google will show its mobile version even if you have marked the page as canonical for the desktop version.
When to Use a Canonical Tag?
Canonical tags are usually used when there are several same pages or URLs on your website. Canonical tags are mainly used in the following cases:
When the homepage of a website can be accessed through multiple URLs,
For example
www.mywebsite.com
http://www.mywebsite.com
https://www.mywebsite.com
mywebsite.com
And so on.
When the HTTPS or HTTP version of a website exists.
When the same content is available for www and non-www versions of websites, or occurs with or without trailing slashes.
When there are AMP and non-AMP versions of pages.
When there is a need to consolidate the link signals coming from various websites. In that case, instead of spreading link signals across multiple URLs, it is consolidated into a single canonical URL.
When you syndicate your own website content across multiple websites, there is a need to specify a canonical URL so that a preferred version of the page appears in SERPs.
When a single post or URL falls under many categories, i.e., www.mywebsite.com/section/SEO, www.mywebsite.com/blog/SEO
When there are multiple versions of the same content on your websites, like the print version, PDF, or AMP.
Why are Canonical Tags Important for SEO?
Canonical tags are important for any SEO strategy as they tell Google which pages are correct or a preferred version of duplicate pages. It helps Google better understand your website content.
Google does not support duplicate content. It will be harder for Google to understand which page to index and rank in search results.
Similarly, it is also hard for it to choose either to spread the link equity across multiple URLs or consolidate it into a single one.
By specifying the preferred versions of your web pages, you indicate to Google to index and rank them in SERPs.
You also hint to Google that this is the preferred URL version, so it cannot distribute the link equity and restrict it to only one URL.
General Guidelines to Implement Canonical Tags
Here are a few basic guidelines you need to stick with while implementing canonical tags:
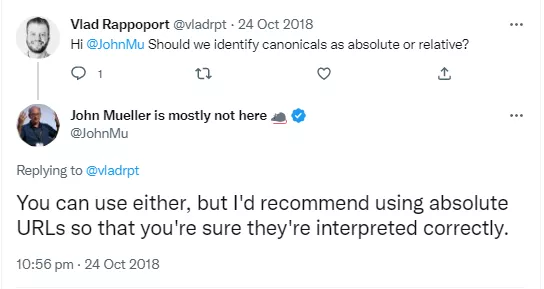
Use an Absolute URL
Absolute URL means the full URL. For example, https://www.mywebsite.com/sample-page is an absolute URL, and Google John Mueller stated that it is ideal to use a complete URL instead of a relative URL (part of the URL that comes after .com).
So the structure of a canonical tag should be like this:
<link rel=“canonical” href=“https://www.mywebsite.com/example-page/” /> Instead of this:
<link rel=“canonical” href=”/example-page/” />Self-Referencing Canonical Tags
Self-referencing canonical means the page containing the canonical tag is pointing towards itself.
John Mueller said that this is not obligatory but recommended.
Use the Correct Domain Protocol
If your website uses the HTTPS protocol, then avoid non-HTTPS URLs while assigning canonical tags.
Use Only One Canonical Tag Per Page
Google recommends using only one canonical tag per page; otherwise, all will be ignored.
Specify no more than one rel=canonical for a page. When more than one is specified, all rel=canonical links will be ignored.
How to Implement a Canonical Tag?
Google encourages using the following methods while specifying the canonical tags, but these are not recommended, as it says:
While we encourage you to use any of these methods, none of them are required. If you don't indicate a canonical URL, we'll identify what we think is the best version or URL.
Use a rel="canonical" Link Tag
One of the simplest methods is using the rel=“canonical” tag in your website’s head section.
If duplicate pages exist on your website, simply add this code to the head section of each duplicate page.
<link rel=“canonical” href=“https://yourwebsite.com/canonical-page/” />Make sure to check the URL of the page you want to indicate to Google as a master page or the main version of other duplicate pages.
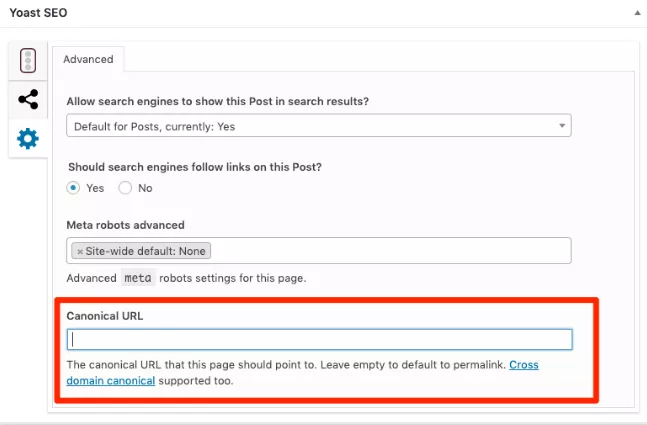
If you are a WordPress user, installing the Yoast SEO plugin will do it for you.
This plugin will add self-referencing canonical tags to all the pages; alternatively, you may select the canonical URLs on your own by going to the “Advanced” section.
Use a rel="canonical" HTTP Header
In the case of PDFs and non-HTML documents, you need to adopt a different strategy to add canonical tags because there is no head section. Here you will use the rel=“canonical” HTTP header to add canonical tags.
You need access to your .htaccess file and specify a canonical tag like this:
Link: <http://www.website.com/downloads/filename.pdf>; rel="canonical"Use a Sitemap
Google suggests adding only canonical URLs to your sitemaps. It considers all URLs in the sitemap as canonical, so you must avoid adding non-canonical URLs to your sitemap.
However, Google says there is no guarantee that we will choose these URLs as canonicals - adding them to your sitemap is just a way of telling Google that you consider these pages important.
Use 301 Redirects
You may also use 301 redirects to divert the traffic from a duplicate page to a canonical URL.
Suppose you have the following versions of your website:
https://yourwebsite.com/home
https://home.yourwebsite.com
https://www.yourwebsite.com
Your website can be accessed through the above-mentioned URLs. Now, you need to choose one as a canonical URL and redirect all others to this canonical version.
You should also do this for your website's HTTPS, non-HTTPS, www, and non-www versions. Suppose the canonical version of seodebate.com is https://www.seodebate.com; then all the below-mentioned URLs will be redirected to this main version.
http://seodebate.com/
http://www.seodebate.com/
https://seodebate.com/
Mistakes to Avoid when Implementing Canonical Tags
Blocking a URL in the Robots.txt File
Sometimes, you block a URL in the robots.txt file and prevent Google from crawling this URL. That means Google will not see a canonical tag on this page and, as a result, will not pass any link equity to the targeted canonical URL.
Use of Noindex Tag
Noindex tags and canonical tags are contradictory, so never use them together.
However, John Mueller says that they prioritize the canonical tags over noindex. But ideally speaking, it is good to avoid using both together.
This is also where the guide that you shouldn't mix noindex & rel=canonical comes from: they're very contradictory pieces of information for us. We'll generally pick the rel=canonical and use that over the noindex.
Not Specifying Canonical Tags with Hreflang Tags
When using hreflang tags, you should also specify a canonical tag for the pages in the same language.
FYI: Hreflang tags inform search engines about the languages in which your website content is available.
Having Multiple Canonical URLs
While specifying a canonical URL, you must stick with only one URL. Otherwise, it may confuse Google, and all tags will be ignored.
This happens when tags are added at multiple places unintentionally, i.e., one tag is hardcoded in the CMS, and another one comes from any plugin.
Be careful while adding them to your page's HTML code; otherwise, it will give mixed signals to Google, and neither of the pages will benefit.
Use of rel=canonical in Body
Rel=canonical tag is always added to the head section of an HTML document. When it is added to the body, Google will ignore it.
How to Find and Fix Canonical Tag Issues?
It is easy to find the issues of the canonical tags with site audit tools. You can use Screaming Frog or any other site audit tools for this purpose.
Duplicate Pages Without Canonical Tags
If there are duplicate pages on your website without canonical tags specifying the most authoritative version, you will see an error regarding this in your site audit report.
Because you haven’t decided on a preferred version of a URL or a page, Google will choose one on its own to index – that may not be the one you wanted as a canonical URL.
So it is ideal to look for duplicate pages in your site audit report and add canonical tags to all the duplicate pages pointing towards the most appropriate page version.
Dead 4XX URL
If a canonical tag points towards a 4XX page, it will create a problem for you as these pages do not exist.
Google will ignore the canonical tags pointing to these URLs and may end up indexing the wrong one.
To fix this problem, see the affected URLs and make sure they return a 200 HTTP status code.
5XX Status Codes
This 5XX status code indicates errors at the server’s end. This indicates that the canonical pages are inaccessible. Thus, Google will not crawl and index them.
This problem may occur temporarily due to server overload or misconfiguration; however, you must check your URLs to see whether they are correct. If URLs are correct, then look for server misconfiguration issues.
Redirects
If the redirects exist on the canonical URLs, Google may ignore them. Canonical tags must point to the most suitable and preferred version of a web page rather than a redirected one.
To fix this issue, make sure to replace the redirected canonical URLs with the direct and most appropriate version of the pages.
Multiple Canonical URLs
This happens when you have multiple canonical URLs specified on a page. Adding multiple canonical URLs on a single page is bad practice.
To fix this problem, keep only one canonical URL in place and remove all others.
Broken Canonical Links
If your duplicate pages are pointing towards broken canonical links, then it will affect the crawling and indexing by Google, as these links do not exist.
To fix this problem, replace the broken canonical URLs with correct and working ones.
Canonical Loops and Chains
Canonical loops and chains are formed when one page points towards another page as canonical, and then this page further points towards another page.
This process creates canonical chains and sometimes never-ending loops. It will confuse the search engine and will waste the crawl budget as well.
Choosing only one preferred or most appropriate version as canonical instead of multiple URLs is ideal.
The Bottom Line
The concept of canonical tags is not new. It has been around since 2009, when Google, Yahoo, and Microsoft launched this concept to solve duplicate content issues.
While using canonical tags, keep in mind that you are only giving a hint to search engines instead of a directive. They may choose your canonical URL as the most authoritative one.
By following the guidelines for choosing the correct canonical URL, you can optimize your website for bots. Don’t forget to check for any canonical issues by using site audit tools and fixing them accordingly.