


What is Googlebot?
Googlebot is a web crawler or spider of Google that collects information from different websites by crawling them. It then makes these web pages or information available for Google Index.
This index is the brain of the computer where all the information resides.
Googlebot searches for fresh and updated content on the internet. It then sends the request to the liable servers.
After getting a response from the respective server, it downloads the web page and stores it in its index. In this way, Google crawls and indexes thousands of pages simultaneously.
Different types of Google bots
Googlebot is the robot of Google, while other search engines have their own.
Below are the most common crawlers or bots used by Google for various services.
APIs-Google
AdSense
AdsBot Mobile Web Android
AdsBot Mobile Web
Googlebot Image
Googlebot News
Googlebot Video
Googlebot Desktop
Googlebot Smartphone
Mobile Apps Android
Mobile AdSense
Feedfetcher
Google Read Aloud
Duplex on the web
Google Favicon
Web Light
Google StoreBot
Google Site Verifier
Each crawler performs a specific task and identifies itself with a series of text called a user agent. In the world of SEO, it is very rare to configure a website for all web bots.
However, they are treated the same way except when you need to put up specific directives for particular crawlers via robots.txt or meta-commands.
How does Googlebot work?
Every search engine, including Google, tries to provide its searchers with the most relevant and up-to-date information.
For that, Google directs its Googlebot to render information on different websites. Googlebot uses the sitemaps and databases of websites during its crawling process.
The bot will add new links to its crawl list if a site has added them to its pages.
If there is any change in the links of a website or there are broken links, Googlebot will take this into account.
If you want Googlebot to crawl your website and index its pages, ensure that your website is available to it and is not blocked by robots.txt.
Googlebot uses its Algorithm (computer programs responsible for matching results from the search index) to determine how often and which sites to crawl.
These crawlers are also programmed to avoid overloading due to overcrawling.
How often does Google crawl your site?
The crawling rate of Google varies from site to site. For big sites - updating their content regularly - Google sends its bots daily or even multiple times in a minute.
On the other hand, different sites are crawled only weekly or monthly.
Googlebot will keep crawling and indexing your web pages and update its index unless you specify and limit its crawling in robots.txt or meta robots tags.
If you want to know how often Googlebot visits your site, go to Google Search Console. Here you will find the Crawl Stats Report of your website under Settings.
How does Googlebot visit your site?
The process of Google search begins with the discovery of URLs and can be divided into three stages:
Discovering
Googlebot discovers the URLs of your website from different sources like backlinks, sitemaps, and manual URL submissions.
Manual URLs are submitted via Google Search Console for crawling and indexing.
Crawling
Google crawlers or bots visit the discovered pages and download different forms of content like text, images, and videos.
Indexing
“Google Index”, also known as “Google’s Brain”, analyses the content or information and stores it in its enormous database.
All the data is stored here in the Search Index and is available to the searchers when they type a particular query regarding this information.
However, getting indexed in Google is important because users will not find your website unless it is indexed.
You can use the Google Search Console to see how Googlebot crawls your website. You may also use the log files or see the Crawl section of your GSC. This section will help you identify the crawl errors as well.
A robots.txt file will also help you see how bots crawl your website. Check this out because if you have done this wrong, you may have stopped the crawlers from reaching out to your website.
How do you optimize your website for Googlebot?
Here are a few ways to optimize your website for Google bots:
See your robots.txt file
The robots.txt file is placed in the root directory of a website domain, telling Google which pages it can access or crawl on your website.
You can optimize this file for Google bots by giving directives to avoid crawling the unnecessary pages or media on your website. It will save the crawl budget for the pages you want Google to index.
Moreover, keep an eye on this file – you may have blocked bots from crawling your website. Make sure you have given the proper directives to Google bots for crawling.
Create a sitemap
It is highly recommended to add your sitemap to your robots.txt. A sitemap is a list of all the pages that exist on your website.
If you have already created a sitemap, bots will easily find all the content on your website.
You can also optimize your sitemap by removing 404 and 301 pages, selecting a few high-priority pages, or keeping pages and blog posts in separate sitemaps.
Website speed
Think about your website speed. If it is too slow, it will discourage the bots from crawling your website.
Check out your site speed using PageSpeed Insights or GTmetrix. See its recommendations and make changes to your website accordingly for better speed.
Have structured data
Having structured data on your website will help Googlebot better understand your website content. Structured data is a format of presenting the information on a page.
For example, on a hotel page, you will have its name, contact information, address, and geolocation.
Make sure to strictly adhere to Google guidelines while adding structured data to your website.
It is good to use JSON-LD data markup, as Google also prefers it.
JSON-LD (JavaScript Object notation for Linked Data) delivers easy-to-understand data from websites to bots like Googlebot.
Request Google Indexing
When you make changes to your website content, update a page, or publish a new one - you don’t need to wait for Google to find and index it.
You can manually send a request to Google in the Google Search Console to index your page.
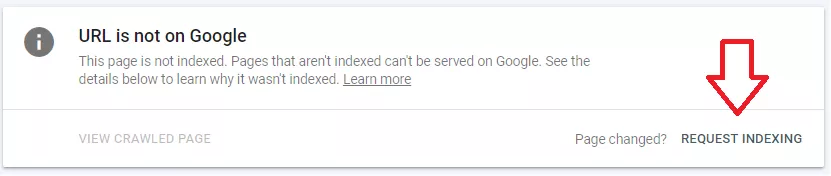
Just "Login" to your GSC account. Enter your "URL". If a URL is already indexed, it will tell you. Otherwise, you may click "Request Indexing".
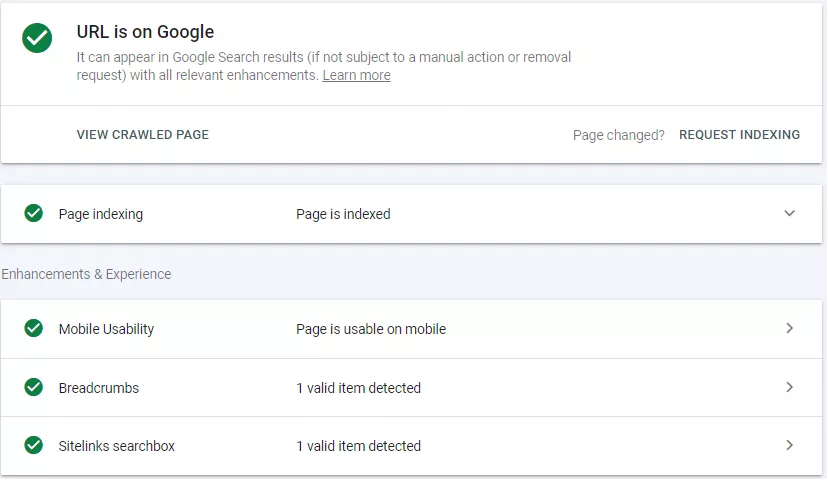
If you frequently add content to your website, request Google to index your pages to ensure the indexing of all pages without delay.
Analyzing Googlebot’s performance
Using Webmaster Tools, you can quickly analyze the performance of Google bots on your website.
In addition, it will give you valuable data to help you optimize your website for bots.
Check the following features of Google Webmaster to see all the data relevant to crawling.
Crawl errors
If there are any crawl errors on your website, the Webmaster tool will identify them. This will raise red flags if it faces any difficulty crawling your website.
These red flags may be an indication of crawl errors like site errors and URL errors.
Crawl statistics
Webmaster tool also gives you statistics on how much data is processed by Google daily. You will positively impact these statistics if you keep posting new and updated content daily.
This indicates your latest content or pages are being crawled and indexed by Google.
Fetching
The “Fetch as Google” feature allows you to see how Google sees your website or specific pages. It helps you analyze your website and find opportunities to make improvements.
URL parameters
Canonical tags can help prevent search engine crawlers from finding duplicate content on pages with URL parameters.
Based on the canonical tags, you can decide which URLs on your website should be crawled by Google bots. It is a quick fix to stop crawlers from finding duplicate content on your website caused by URL parameters.
With a proper canonical tag, your site will be crawled more efficiently using less bandwidth and indexing original content.
Googlebot Limitations
As we've seen, Googlebot is a powerful and sophisticated web crawler. It has many features that make it well-suited for crawling and indexing the web.
However, there are also some limitations to consider.
In particular, keep in mind that:
Googlebot does not execute Javascript. This means that any content that is generated by Javascript will not be crawled or indexed by Googlebot.
Googlebot does not render web pages in the same way that a web browser does. This can sometimes lead to differences between the way a page looks to Googlebot and the way it looks to a human visitor.
Googlebot is subject to the same limitations as any other web crawler. This means that it can sometimes miss content or index outdated content.
How to verify Googlebot?
Different malicious software/bots act like Googlebot; they do so to access the websites that have blocked them.
Recently Google has made it very easy to verify the Googlebot. Earlier, it was done manually by running a DNS lookup to verify the Googlebot.
Google has provided a list of public IPs that can be used to confirm that the requests are from Google by comparing these IPs with the IP of the crawler. This data can be accessed and compared in server logs.
Go to Google Search Console > Settings > Crawl Stats
Here you will find the report that will show you how Google is crawling and accessing different files.

The bottom line
Understanding the functionality of Googlebot is complex and requires a lot of technical knowledge.
However, how Googlebot crawls your website is still an essential skill to learn for anyone who wants to improve their website's visibility in Google Search.
By understanding how Googlebot works, and how to use it effectively, you can make sure that your website is being crawled and indexed properly, and that your content is visible to potential customers.