


What is scraped content?
The data or information that has been automatically extracted or copied from other websites is called scraped content. This can be done manually or using tools called web scrapers or crawlers.
It may include text, images, videos, and other types of data.
This extracted content is then used for various purposes, like creating duplicate websites or selling the data to third parties.
How do scrapers work?
Web scrapers send automated requests to a website. They parse the HTML code of the webpage and extract the relevant data based on certain criteria such as keywords.
This process can be done manually or by using specific tools. Manual work is tedious. So tools are used to make this process faster.
These tools are customized according to the website, its content, and data types.
Web scraping can be a useful tool for data collection or analysis but it can also be controversial, especially if it is done without permission.
Type of content that is scraped
Here are some common types of content that are often scraped:
Text content such as articles, blog posts, and user-generated content.
Images and videos.
Product descriptions and pricing information.
Contact information, like email addresses, phone numbers, and physical addresses.
Social media content.
News articles and press releases.
Research data and scientific articles from academic journals.
Job listings and career information from recruitment sites.
Real estate listings.
Financial data like exchange rates and economic indicators.
Why do people scrape content?
There are several reasons for that. One main reason is to get data like customer reviews, social media sentiment analysis, or stock prices.
Another reason is to collect content to create a new website that provides value to users.
For instance, a travel website can scrape information from multiple airline and hotel websites to provide information in one place.
Unfortunately, some people scrape content to create duplicates of popular websites to generate revenue.
On the other hand, some do this for malicious purposes, like stealing personal information and committing fraud.
Note: One important thing to remember is that you should not confuse it with content syndication. Content syndication is a completely legitimate and legal practice. To make it understandable, let's know the difference between both.
Difference between content scraping and syndication
Content scraping and syndication are two different practices, although they are often confused with each other.
In content scraping, you copy the content of other websites without permission and use it for your own benefit without crediting the owner.
On the other hand, in content syndication, you publish the content of other websites on your own website with the permission of the author.
Content scraping is usually done in a negative way while syndication focuses on providing valuable content to a wider audience.
Also, you do not get the permission of the author or website owner in case of scraping. While in content syndication, you properly mention the source and credit the website or author.
Why is it bad for SEO?
Content scraping can lead to duplicate content which can harm a website's rankings.
When search engines crawl through websites, they use algorithms to identify duplicate content.
If a website's content is found to be duplicated, the search engine may not know which version to prioritize, which can result in a lower ranking for all.
Furthermore, content scraping can damage a website's credibility, as it may appear to users that the scraped content is original when in fact it is not.
This can lead to a loss of trust and a decrease in user engagement.
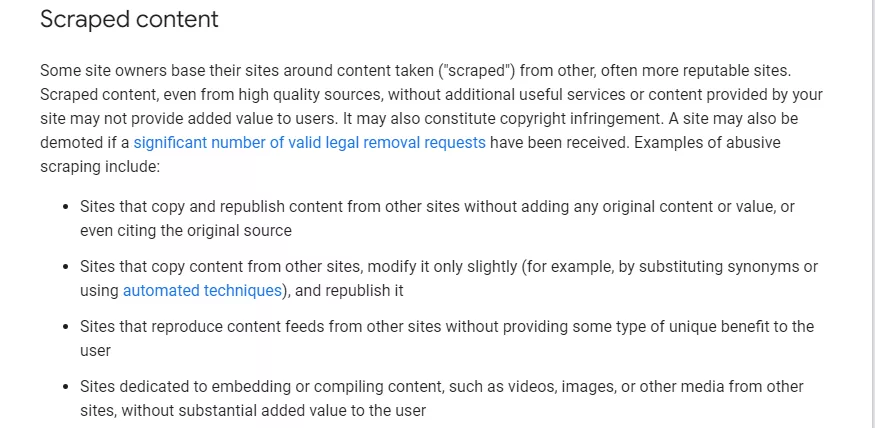
Here is what Google says about Scraped content in its Spam Policies:
Why is content scraping Controversial?
Content scraping was controversial because it raised several ethical and legal concerns.
First, it was a form of intellectual property theft, as it involved the unauthorized use of someone else's content.
Nonetheless, it is not like that now because a ruling by the 9th Circuit Court of Appeals did not bar the scraping of public websites.
It means that as long as the content is not used for malicious purposes or from public websites, it is okay to use.
On the other hand, it is still controversial because it can harm a site's reputation if it is used for malicious or illegal activities.
How do you know whether your website is being scraped or not?
Here are some ways to determine if your content has been scraped:
Use a plagiarism checker
There are several free and paid plagiarism checkers that can help you identify duplicate content.
Simply copy and paste a section of your content into the checker and it will search for matches across the web.
Some of the best tools are:
Copyscape
Grammarly plagiarism checker
Quetext
Monitor your website traffic
If you notice a sudden decrease in website traffic, it may be a sign that your content has been scraped.
Use website analytics tools such as Google Analytics to monitor your traffic and identify any unusual patterns.
Set up Google Alerts
Google Alerts is a free tool that allows you to monitor the web for specific keywords.
Set up alerts for your website name, brand, or specific content to receive notifications when your content appears on other sites.
Use a web scraping detection tool
There are several paid tools available that can detect instances of content scraping and notify you when it occurs.
These tools use advanced algorithms to search the web and provide detailed reports on where and how a piece of content is being used.
Some best tools are:
Distil Networks
Imperva
Akamai Bot Manager
Search for your content
Use a search engine to look for exact phrases or sentences from your content.
If the same content appears on another website, someone is likely scraping your content.
How to Prevent Content Scraping?
There are several methods you can use to prevent content scraping. These include:
CAPTCHA
CAPTCHA is a commonly used method to prevent bots from accessing a website.
It presents a challenge to the user, usually in the form of distorted text or an image that the user must correctly identify to proceed.
This challenge is difficult for bots to solve, as it requires human-like perception and cognitive abilities.
You can implement CAPTCHA on your website to avoid bots.
IP Blocking
IP blocking is a method of preventing access to a website by identifying and blocking the IP addresses of bots.
By monitoring traffic, it is possible to identify IP addresses that are associated with bots and block them.
This method is particularly effective against bots that repeatedly attempt to access a website from a specific IP address.
Rate Limiting
Rate limiting is a method of limiting the number of requests that a bot can make to a website within a specific timeframe.
You can impose limits on the number of bot requests to avoid overwhelming your site's resources and slowing down its performance.
Bot Detection Tools
There are a variety of software tools available to help detect and prevent bots from accessing a site.
These tools use various methods like browser fingerprinting and machine learning algorithms to identify bot traffic.
Some of the best tools are:
SolarWinds Security Event Manager
ManageEngine NetFlow Analyzer
Cloudflare Bot Manager
Radware Bot Manager
Website Monitoring
Regularly monitoring website traffic and analyzing patterns can help identify bot traffic and determine if any additional measures are needed to avoid them.
Catching bots with a honeypot
A honeypot is a fake area of a website that is designed to attract bots. It appears to be a legitimate part of the website but is hidden from regular users.
When a bot accesses the honeypot, it can be identified and its IP address can be logged.
This IP can then be added to a blacklist to restrict it from accessing the site.
Blocking bots with JavaScript code
JavaScript can be used to detect whether a browser supports certain features that bots typically do not use, such as mouse movements or touch events.
If the browser does not support these features, the website can assume that it is being accessed by a bot and prevent access.
However, these methods are not completely reliable as advanced bots can work around them.
Copyright notice
Adding a copyright notice to the website informs visitors that the content is protected by copyright law.
DMCA (Digital Millennium Copyright Act)
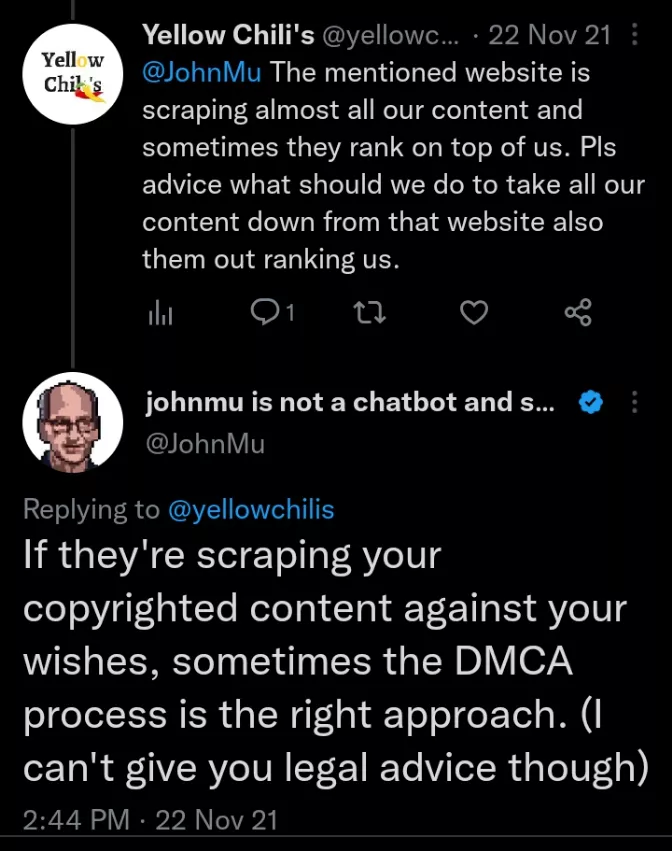
You can also go for legal measures such as sending cease-and-desist letters or filing a DMCA takedown notice to force the scraper to remove the content.
That’s what John Mueller tweeted a reply about:
API (Application Programming Interface)
To use an API to control scraping, you can provide access to your data through a set of defined endpoints that require authentication and other security measures.
This will allow controlled access to the content and track its usage.
Conclusion
Content scraping presents challenges such as duplicate content, SEO issues, and credibility risks. Website owners should proactively implement measures to protect their original content.
It helps maintain website integrity and ensures the ethical use of digital information.