


What Are Total Crawl Requests?
Total crawl requests refer to the total number of individual requests that a search engine's crawler makes to access all the various content pieces on a website over a particular period of time.
Most tools measure over daily or monthly periods.
For example, if Googlebot accessed and requested:
1,000 different pages
500 images
100 PDFs From your website over the last 30 days, your total crawl requests for that month would be 1,600 requests.
Each time a crawler visits a page on your site, it counts as a crawl request.
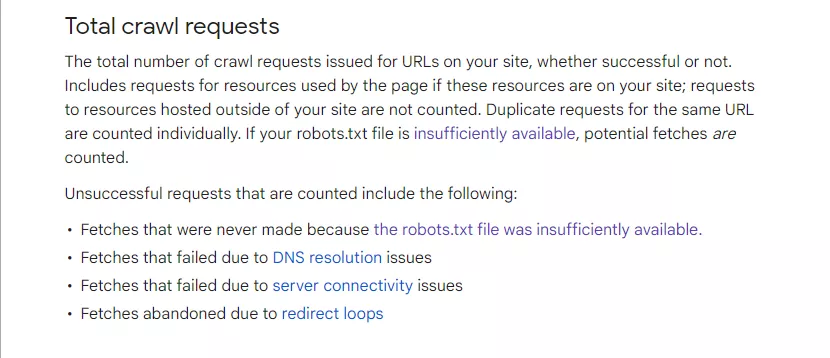
This is how Google describes the process of determining a website's crawl request.
Why Crawl Requests Matter
Tracking and managing your website's total crawl requests is important for several reasons:
Crawl Budget Management: Search engines set limits on the total number of requests they'll allow from any given website over a set timeframe. This is called a "crawl budget."
You want the crawler to focus its budget on requesting your most important pages and content, rather than wasting requests on lower-priority areas.
Site Performance: If Googlebot and other crawlers make too many requests too quickly, it can overload your server resources and negatively impact your website's performance for real visitors.
Avoiding Blocklisting: Going significantly over your crawl budget limit risks getting your website temporarily blocklisted, meaning search engines will stop requesting new content until the situation is resolved.
Essentially, maintaining a reasonable volume of total crawl requests ensures search engines can properly access and index your content without negatively impacting factors like site performance or causing penalties.
What Factors Increase Crawl Requests?
Several factors can drive up the total number of requests a crawler makes:
Overall website size (the more pages, files, media, etc.)
Frequency of publishing new pages/updates
Complex or messy website architecture with excessive redirects, broken links, etc.
Settings in Search Console like crawl rate
Optimizing Total Crawl Requests
Most websites will naturally generate a steady volume of crawl requests, which is expected and okay.
However, monitoring your totals through tools like Google Search Console and Log File Analysis can alert you to any sudden spikes or worrying trends.
If you notice crawl requests ramping up drastically, that could be a sign of underlying issues like:
Crawl budget saturation (being overused on the wrong content)
Crawler capacity being exceeded (timeouts, server overload, etc.)
Crawl issues like redirect chains, crawl holes, etc.
Using those diagnostics can help you pinpoint areas to optimize your site's architecture, URL configurations, performance, and other factors to rein in total requests to a more manageable, prioritized level.
The key is facilitating smoother, more efficient crawling while avoiding scenarios where bots get bottlenecked or overwhelm your servers with excessive requests.
With the right monitoring and optimization strategies, you can maximize your search engine's crawl effectiveness without sacrificing performance or user experience for real visitors to your site.